
This time an article that aims towards the more traditional Product Lifecycle Management domain and especially towards configurable products or so called Configure To Order (CTO) products. This article is a direct result of discussions I’ve had with Henrik Hulgaard, the CTO of Configit, on Configuration Management in general and Product Configuration Management in particular. Configit specializes in Product Configuration Management, or as they prefer to call it Configuration Lifecycle Management.
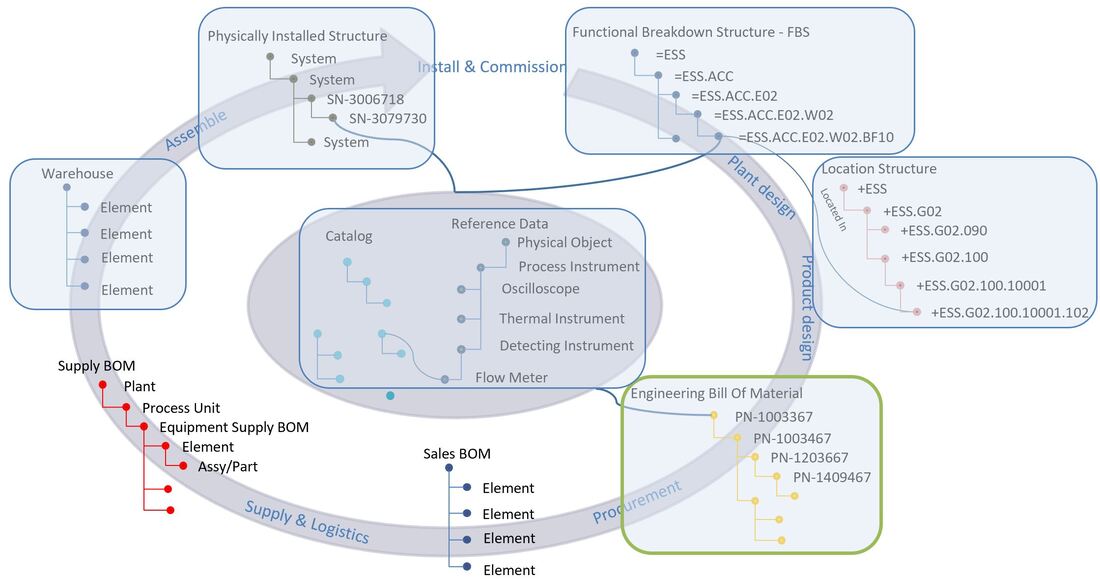
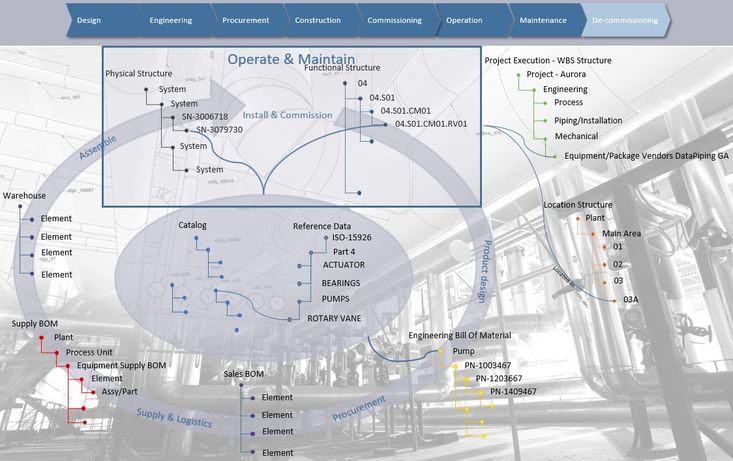
Most businesses that design, manufacture and sell products have a system landscape in place to support key areas during the lifecycle of a product pretty much as in the image below (there are of course differences from company to company).
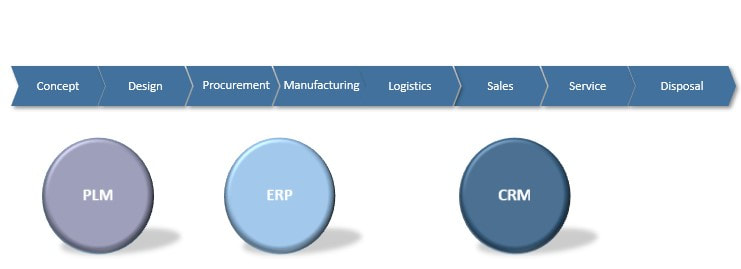
Figure 1.
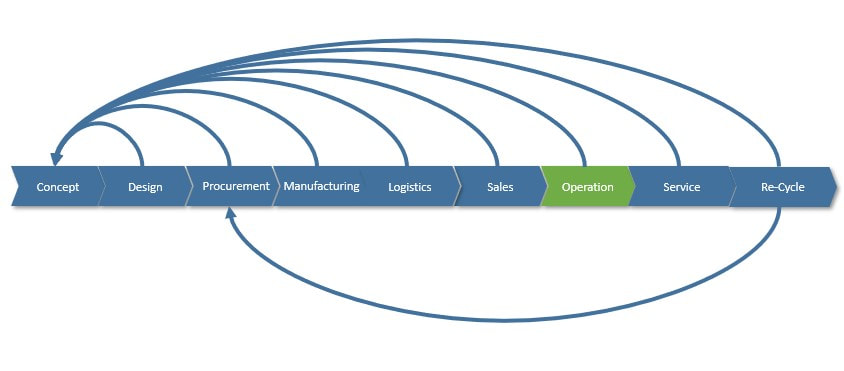
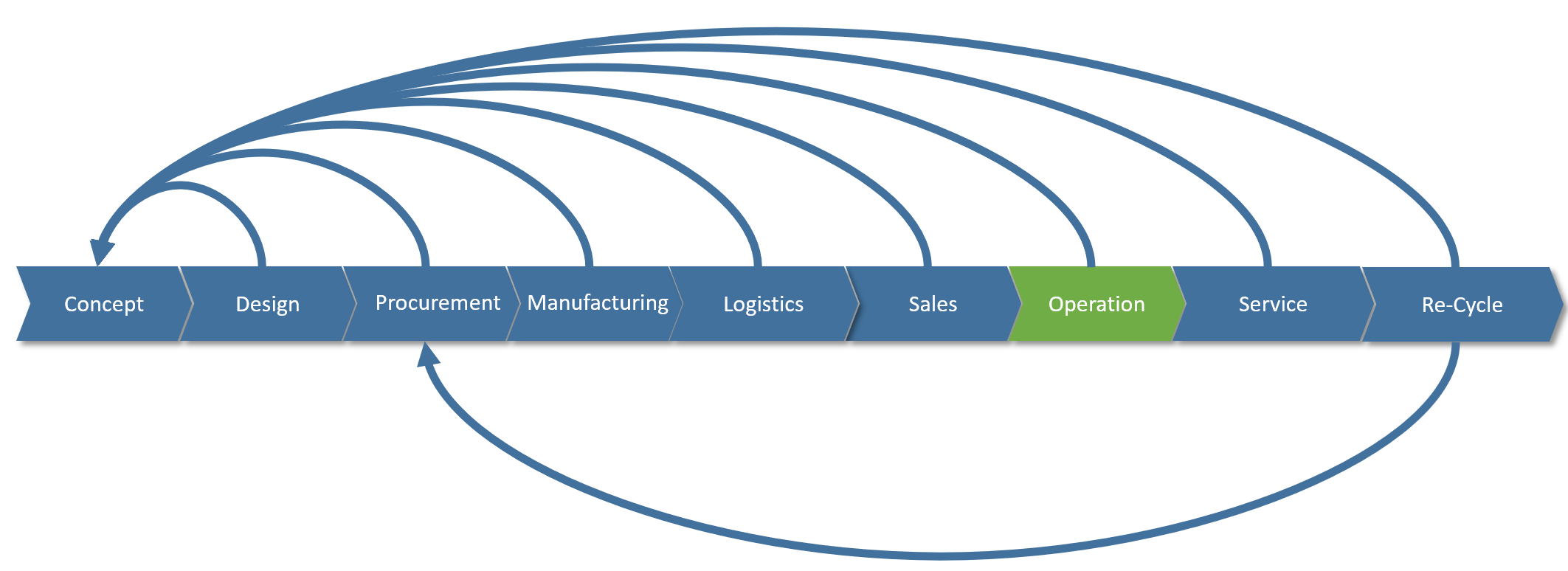
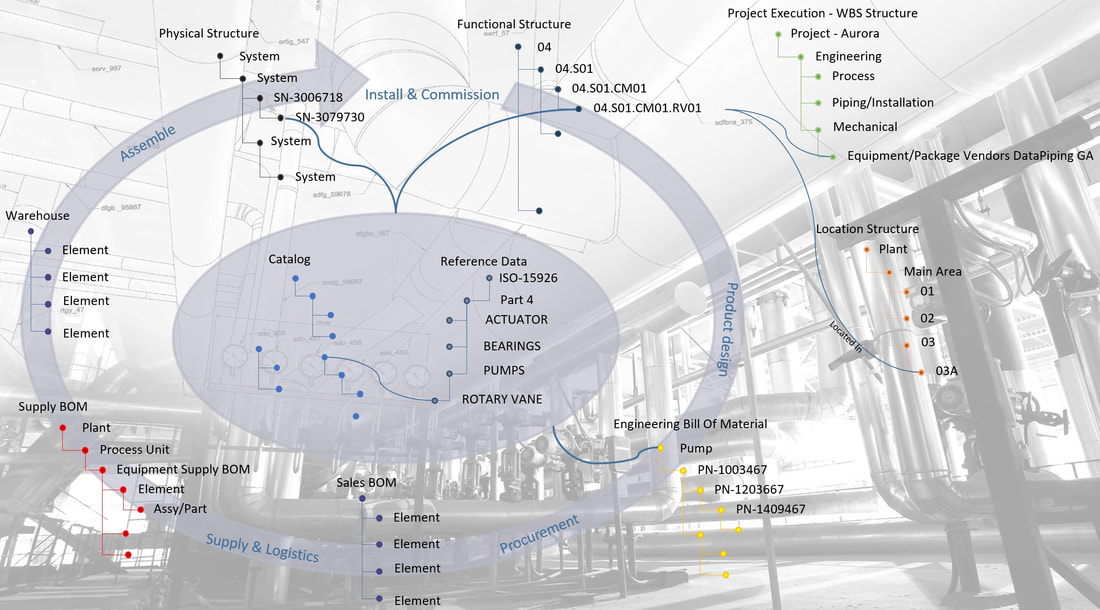
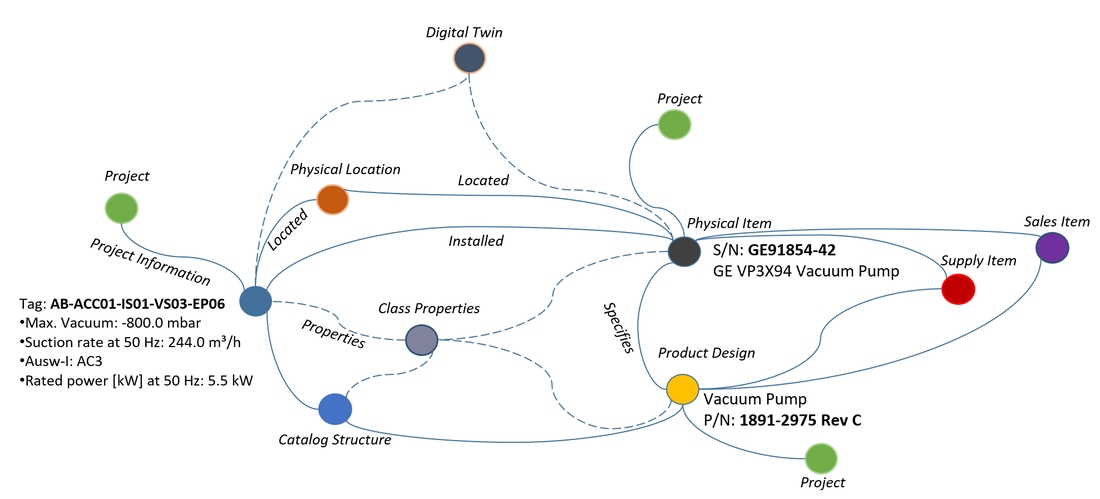
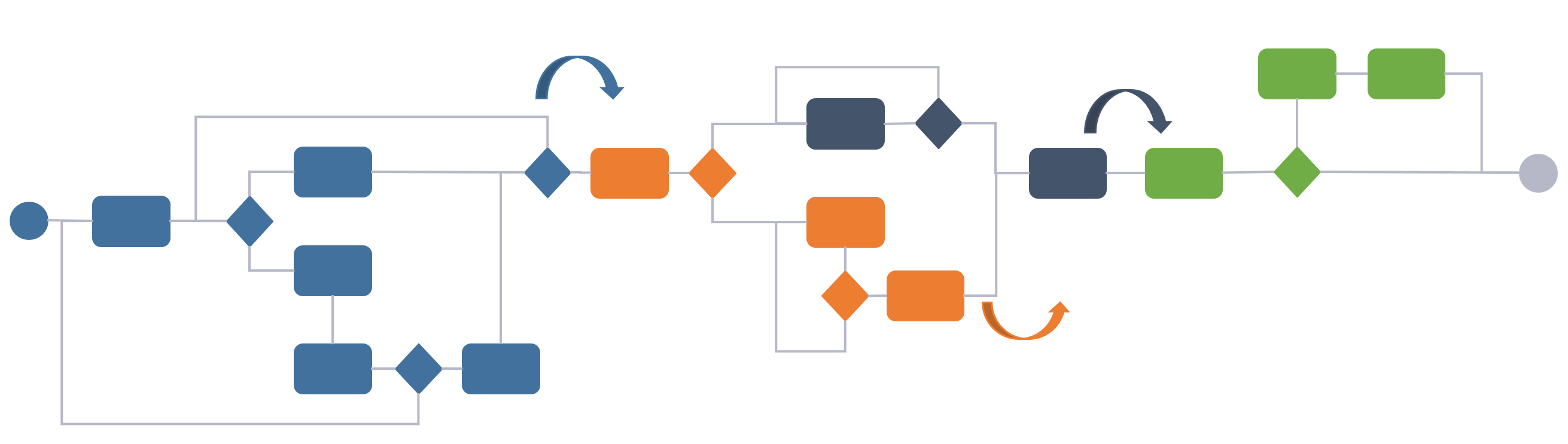
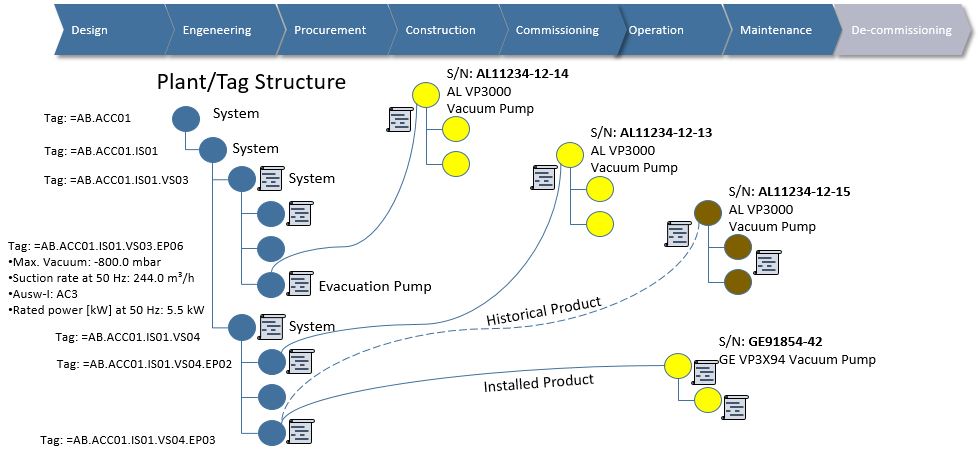
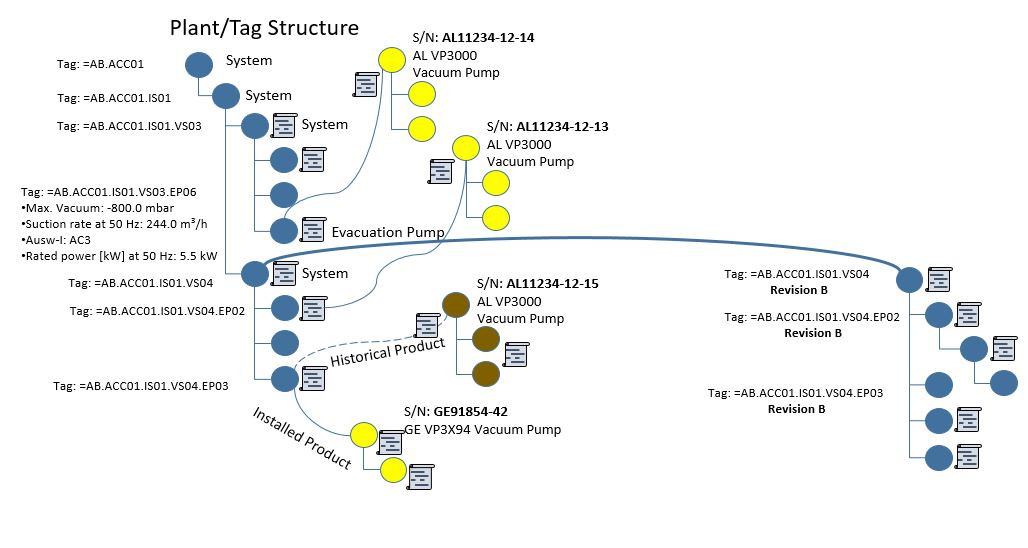
This works well as long as the product lifecycle is linear, like it has mostly been in the past. However, as more and more companies strive after being able to let customers “personalize” their products, (so, to configure them to support their individual personal needs), harvest data and behavior from “the field” through sensors to detect trends in usage as well as being able to offer new services while the product is in use (operational), the lifecycle cannot be linear anymore in my view. This is because all phases of the lifecycle need feedback and information from the other phases to some degree. You may call this “a digital thread”, “digital twin” or “digital continuity” if you will (figure 2).
This works well as long as the product lifecycle is linear, like it has mostly been in the past. However, as more and more companies strive after being able to let customers “personalize” their products, (so, to configure them to support their individual personal needs), harvest data and behavior from “the field” through sensors to detect trends in usage as well as being able to offer new services while the product is in use (operational), the lifecycle cannot be linear anymore in my view. This is because all phases of the lifecycle need feedback and information from the other phases to some degree. You may call this “a digital thread”, “digital twin” or “digital continuity” if you will (figure 2).
Figure 2.
Such a shift puts enormous requirements on traceability and change management of data all the way from how the product was designed, through to how it is used, how it is serviced and ultimately how it is recycled. If the product is highly configurable, the number of variants of the product that can be sold and used is downright staggering.
Needless to say, it will be difficult to offer a customer good service if you do not know what variant of the product the customer has purchased, and how that particular instance of the product has been maintained or upgraded in the past.
So, what can a company do to address these challenges and also the vast opportunities that such feedback loops offer?
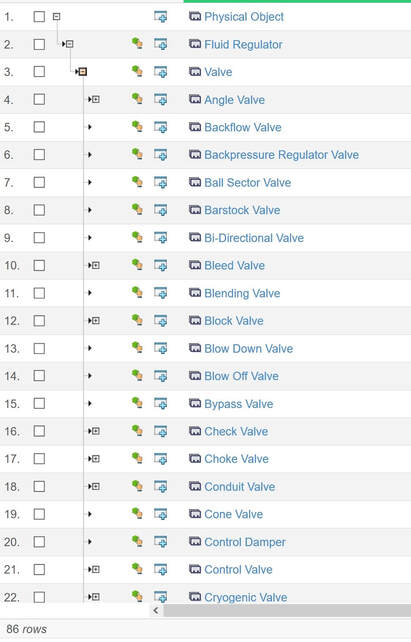
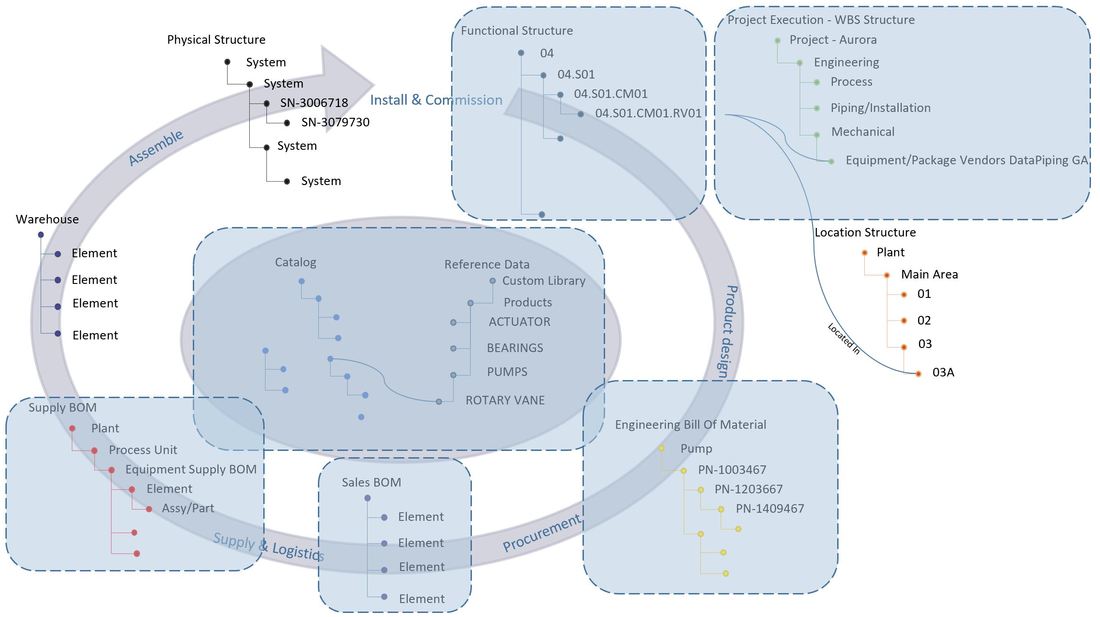
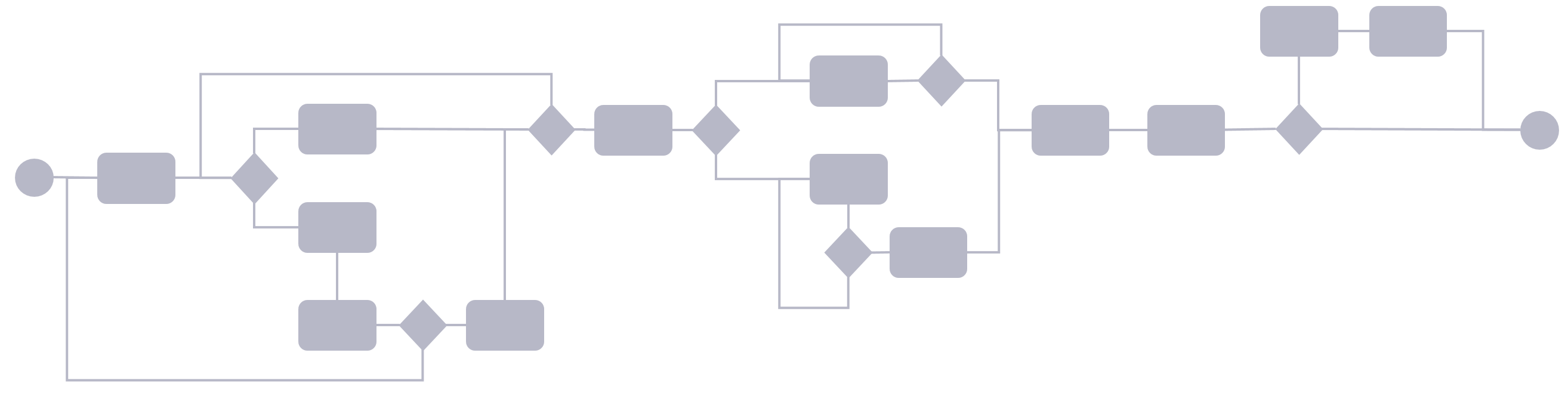
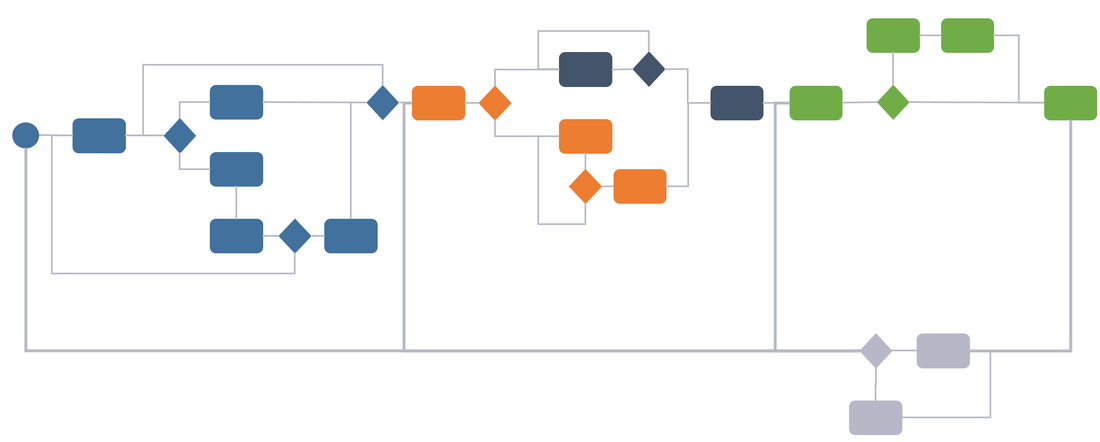
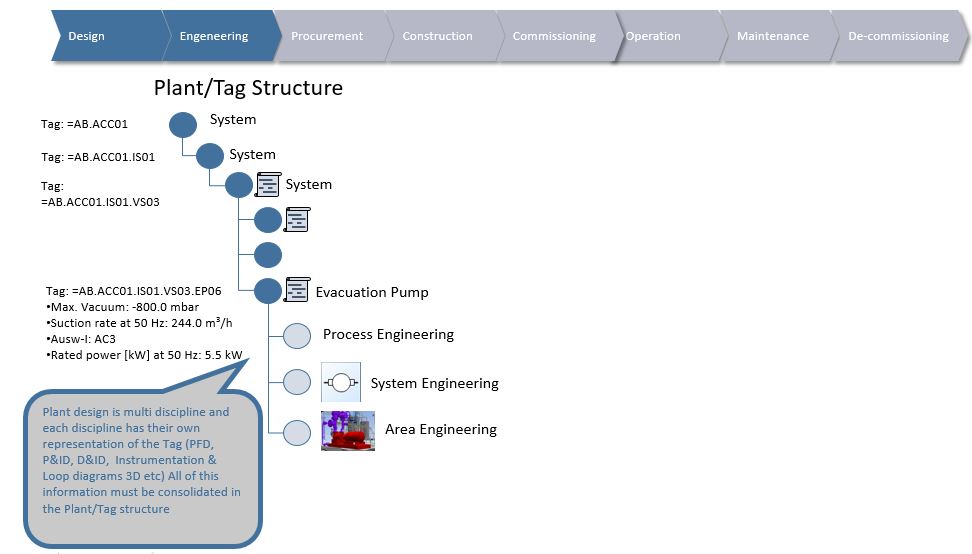
If we consider the three system domains that are normally present (there are often more), they are more often than not quite siloed. That is in my experience not because the systems cannot be integrated, but more as a result of organizations still working quite silo oriented (Figure 3).
Such a shift puts enormous requirements on traceability and change management of data all the way from how the product was designed, through to how it is used, how it is serviced and ultimately how it is recycled. If the product is highly configurable, the number of variants of the product that can be sold and used is downright staggering.
Needless to say, it will be difficult to offer a customer good service if you do not know what variant of the product the customer has purchased, and how that particular instance of the product has been maintained or upgraded in the past.
So, what can a company do to address these challenges and also the vast opportunities that such feedback loops offer?
If we consider the three system domains that are normally present (there are often more), they are more often than not quite siloed. That is in my experience not because the systems cannot be integrated, but more as a result of organizations still working quite silo oriented (Figure 3).
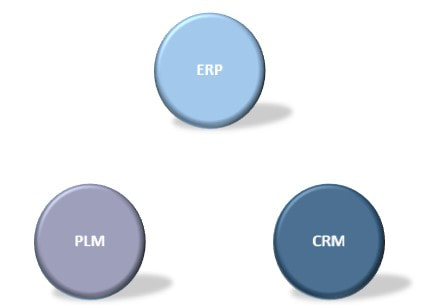
Figure 3.
All companies I’ve worked with wants to break down these silos and internally become more transparent and agile, but what domain should take on the responsibility to manage the different aspects of product configuration data? I mean, there is the design & engineering aspect, the procurement aspect, the manufacturing aspect, the sales aspect, the usage/operation aspect, the service/maintained aspect and ultimately the recycling aspect.
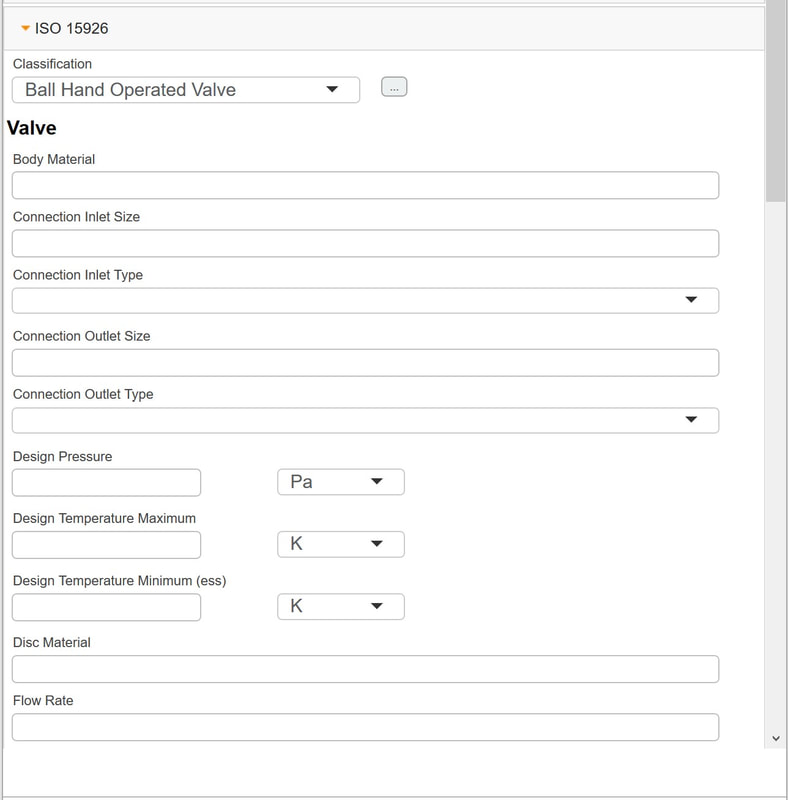
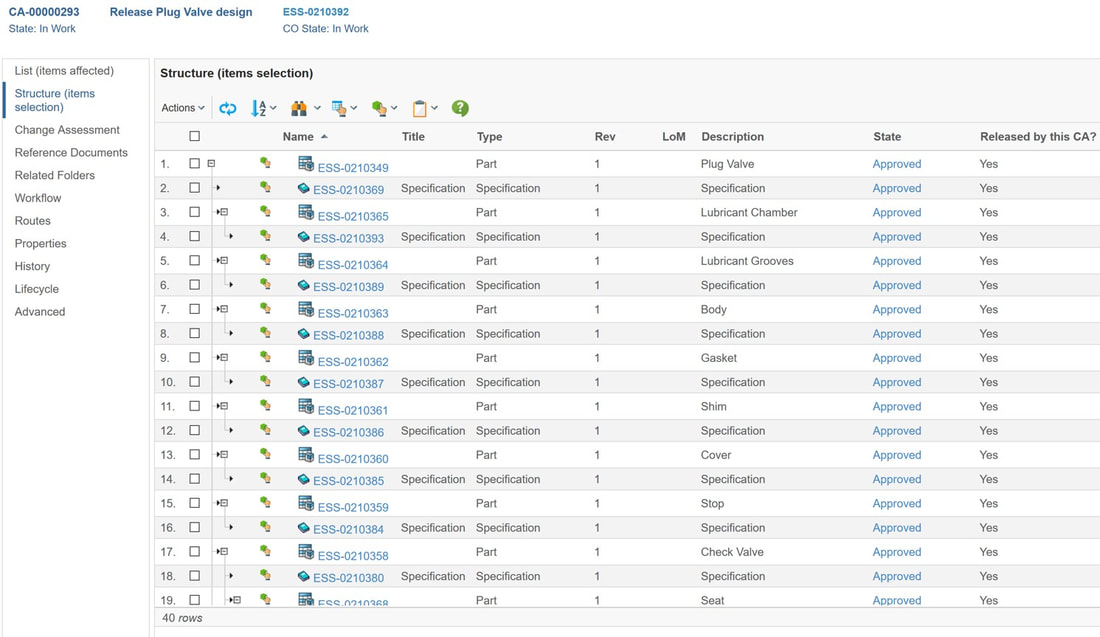
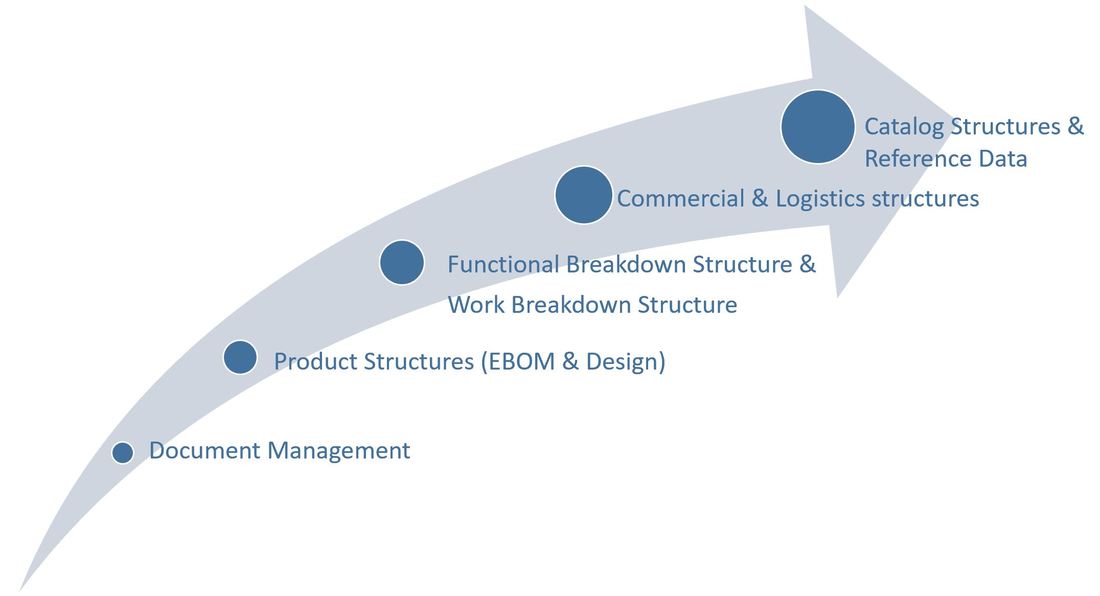
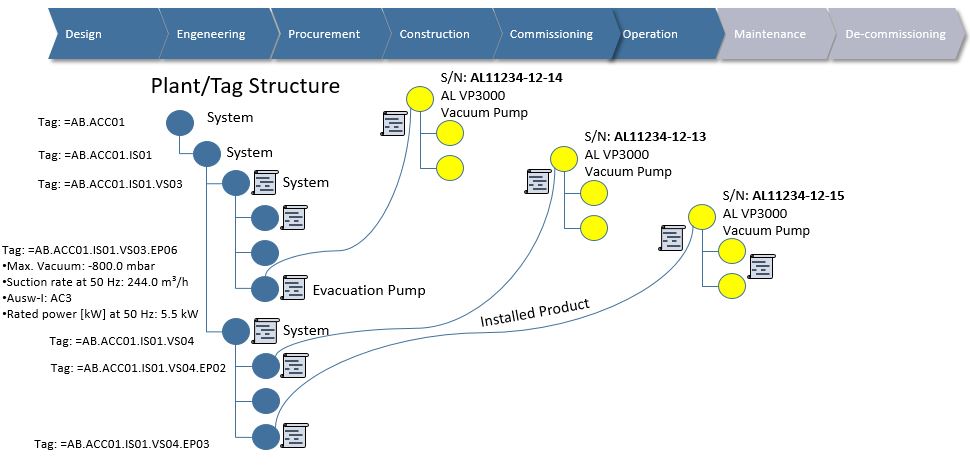
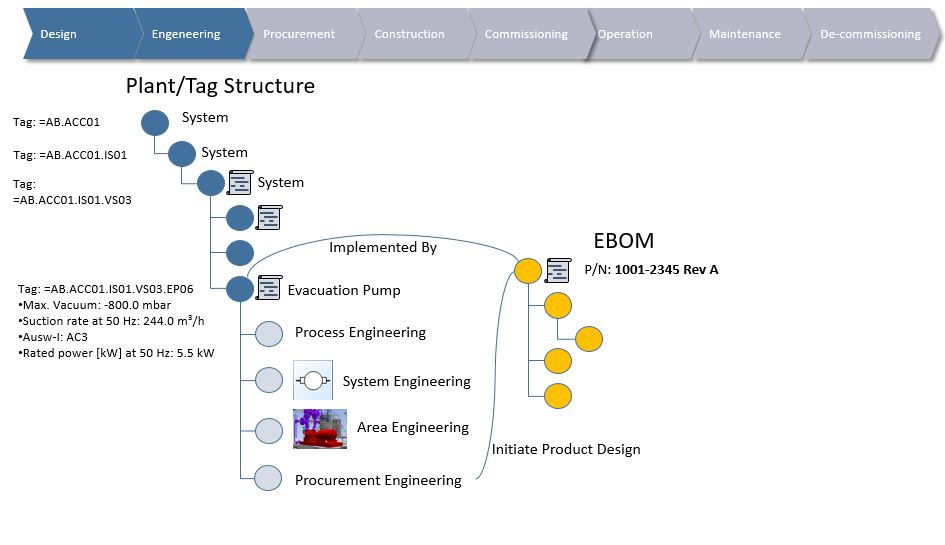
Several PLM systems today have configuration management capabilities, and it would for many companies make sense to at least manage product engineering configurations here, but where do you stop? I mean, sooner or later you will have to evaluate if more transactional oriented data should be incorporated in the PLM platform which is not a PLM system’s strongpoint (figure 4).
All companies I’ve worked with wants to break down these silos and internally become more transparent and agile, but what domain should take on the responsibility to manage the different aspects of product configuration data? I mean, there is the design & engineering aspect, the procurement aspect, the manufacturing aspect, the sales aspect, the usage/operation aspect, the service/maintained aspect and ultimately the recycling aspect.
Several PLM systems today have configuration management capabilities, and it would for many companies make sense to at least manage product engineering configurations here, but where do you stop? I mean, sooner or later you will have to evaluate if more transactional oriented data should be incorporated in the PLM platform which is not a PLM system’s strongpoint (figure 4).
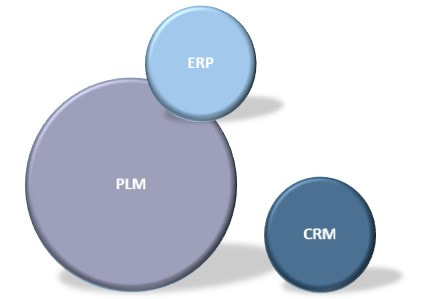
Figure 4.
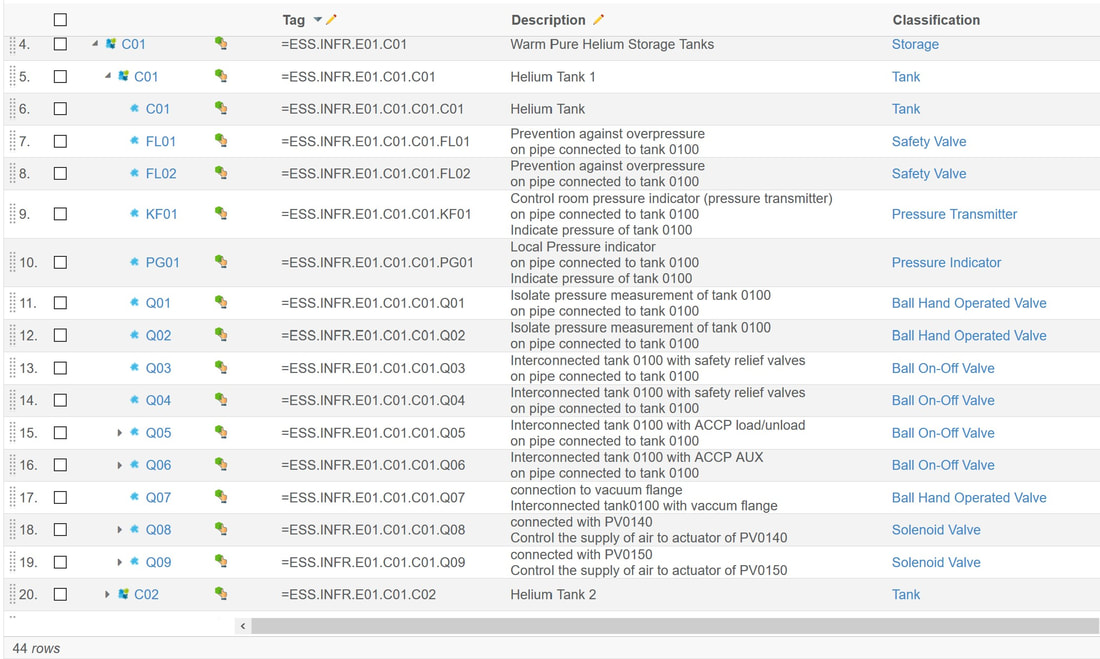
On the other hand, several ERP systems also offer forms of configuration management either as an addition or as part of their offering. The same question needs to be answered here. Where does it make most sense to stop as ERP systems are transactional oriented, while PLM systems are a lot more process and iteratively work oriented (figure 5).
On the other hand, several ERP systems also offer forms of configuration management either as an addition or as part of their offering. The same question needs to be answered here. Where does it make most sense to stop as ERP systems are transactional oriented, while PLM systems are a lot more process and iteratively work oriented (figure 5).
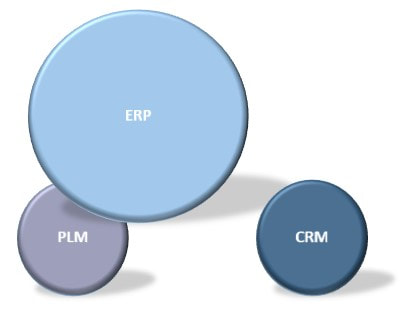
Figure 5.
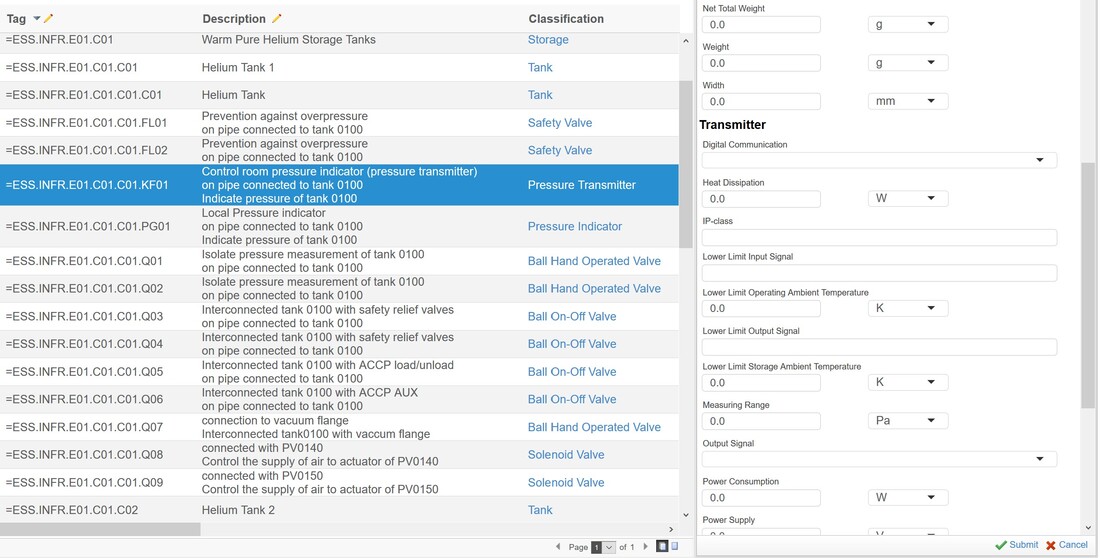
The same questions need to be asked and answered for the scenario regarding CRM. Where does it make sense to draw the boundaries towards ERP or PLM, like in figure 6.
The same questions need to be asked and answered for the scenario regarding CRM. Where does it make sense to draw the boundaries towards ERP or PLM, like in figure 6.
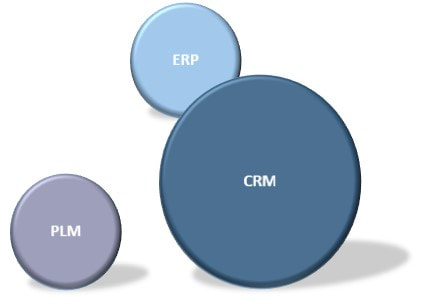
Figure 6.
I have seen examples of companies wanting to address all aspect with a single software vendor’s portfolio, but in my experience, it only masks the same questions within the same portfolio of software solutions. Because, who does what, where and with responsibility for what type of data when, is not tackled by using a single vendor’s software. Those are organizational, and work process related questions, not software questions.
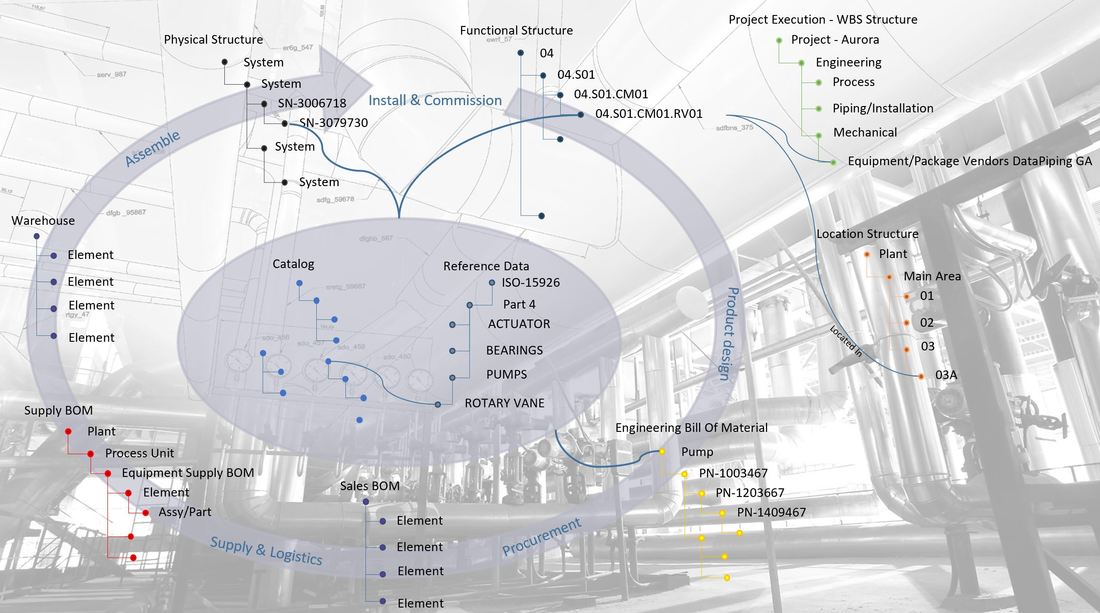
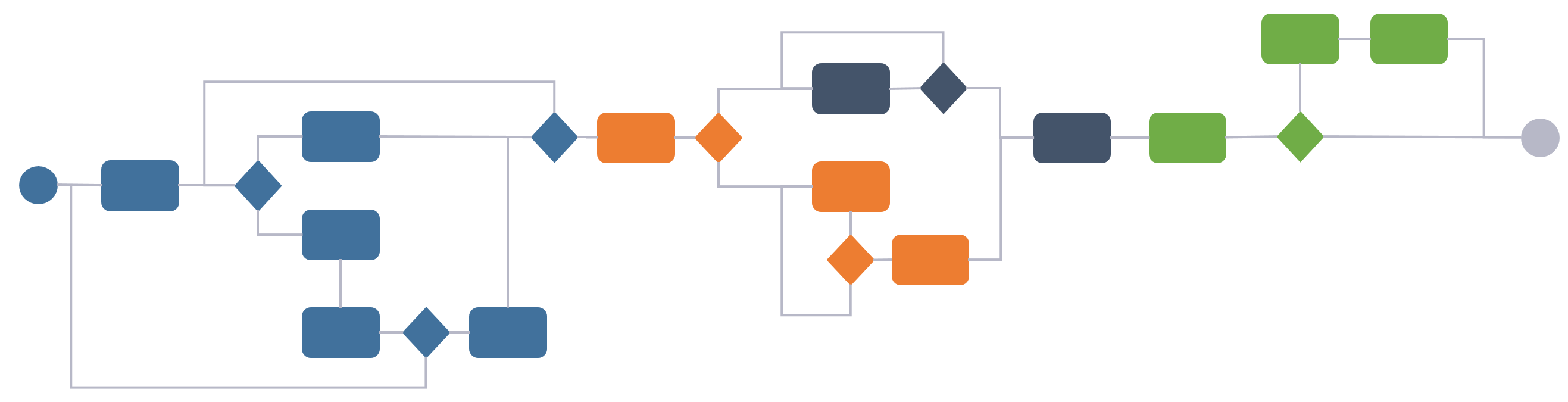
Another possible solution is to utilize what ERP, PLM and CRP systems are good at in their respective domains, and implement the adjoining business processes there. Full Product Configuration Management or Configuration Lifecycle Management needs aspects of data from all the other domains to effectively manage the full product configuration, so a more domain specific Configuration Management platform could be introduced.
I have seen examples of companies wanting to address all aspect with a single software vendor’s portfolio, but in my experience, it only masks the same questions within the same portfolio of software solutions. Because, who does what, where and with responsibility for what type of data when, is not tackled by using a single vendor’s software. Those are organizational, and work process related questions, not software questions.
Another possible solution is to utilize what ERP, PLM and CRP systems are good at in their respective domains, and implement the adjoining business processes there. Full Product Configuration Management or Configuration Lifecycle Management needs aspects of data from all the other domains to effectively manage the full product configuration, so a more domain specific Configuration Management platform could be introduced.
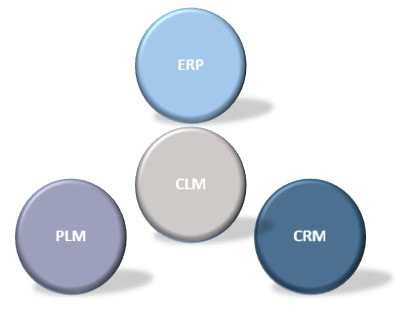
Figure 7.
Such a platform will have to be able to reconcile information from the other platforms and tie it together correctly, hence it would need a form of dictionary to do that. In addition, it needs to define or at least master the ruleset defining what information from PLM can go together with what information in ERP and CRM to form a valid product configuration that can legally be sold in the customer’s region.
As an example, consider: What product design variant that meets the customer requirements can be manufactured most cost effectively and nearest the customer with the minimal use of resources and still fulfill regulatory requirements in that customers country or region?
These are some of the questions that must be answered.
More strategic reasons to evaluate a setup like in figure 7 could be:
I would very much like to hear your thoughts on this subject.
Bjorn Fidjeland
The header image used in this post is by plmPartner
Such a platform will have to be able to reconcile information from the other platforms and tie it together correctly, hence it would need a form of dictionary to do that. In addition, it needs to define or at least master the ruleset defining what information from PLM can go together with what information in ERP and CRM to form a valid product configuration that can legally be sold in the customer’s region.
As an example, consider: What product design variant that meets the customer requirements can be manufactured most cost effectively and nearest the customer with the minimal use of resources and still fulfill regulatory requirements in that customers country or region?
These are some of the questions that must be answered.
More strategic reasons to evaluate a setup like in figure 7 could be:
- As the departmental silos in an organization is often closely linked to the software platform domain, it might be easier to ensure collaboration and acceptance by key stakeholders across the organization with a “cross-cutting” platform that thrives on quality information supplied by the other platforms.
- It poses an opportunity for companies with a strategy of not putting too many eggs in the basket of one particular software system vendor.
- It could foster quality control of information coming from each of the other domains as such a CLM solution is utterly dependent on the quality of information from the other systems.
- Disconnects in the information from the different aspects can be easily identified.
I would very much like to hear your thoughts on this subject.
Bjorn Fidjeland
The header image used in this post is by plmPartner













 RSS Feed
RSS Feed
