

A vital questions when looking at cross departmental process optimization and integration is in my view: who owns what data when in the overall process?
Usually this question will spark up quite a discussion between the process owners, company departments, data owners and the different enterprise architects. The main reason for this is that depending on where the stakeholders have their main investment, they tend to look at “their” part of the process as the most important and the “master” for their data.
Just think about sales with their product configurators, engineering with CAD/PLM, supply chain, manufacturing & logistics with ERP and MES. Further along the lifecycle you encounter operations and service with EAM, Enterprise Asset Management, systems sometimes including MRO, Maintenance Repair and Operations/Overhaul. The last part being for products in operational use. Operations and service is really on the move right now due to the ability to receive valuable feedback from all products used in the field (commonly referred to as Internet of Things) even for consumer products, but hold your horses on the last one just for a little while.
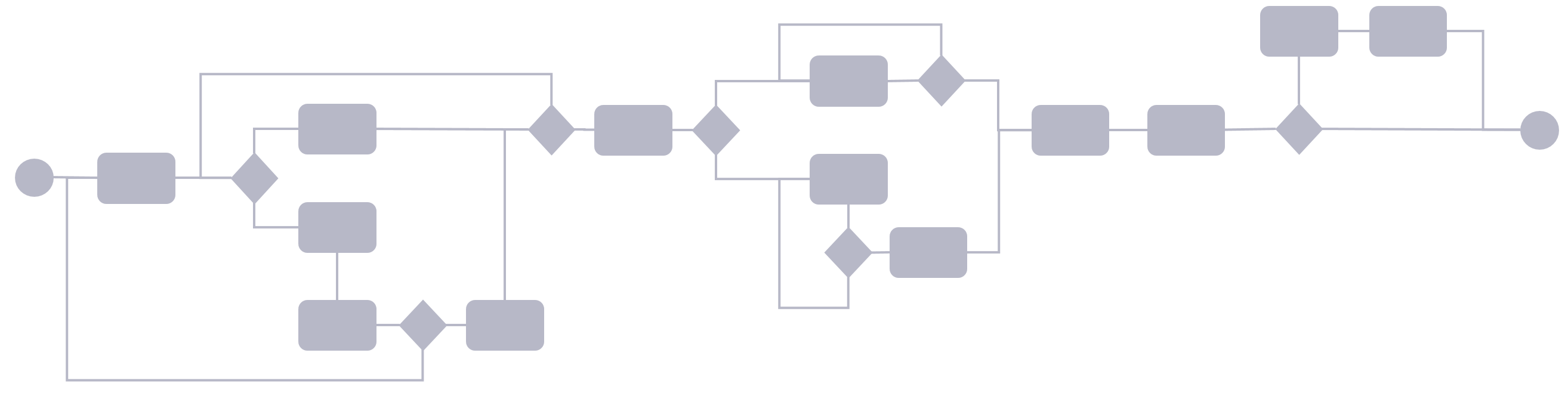
The different departments and process owners will typically have claimed ownership of their particular parts of the process, making it look something like this:
Just think about sales with their product configurators, engineering with CAD/PLM, supply chain, manufacturing & logistics with ERP and MES. Further along the lifecycle you encounter operations and service with EAM, Enterprise Asset Management, systems sometimes including MRO, Maintenance Repair and Operations/Overhaul. The last part being for products in operational use. Operations and service is really on the move right now due to the ability to receive valuable feedback from all products used in the field (commonly referred to as Internet of Things) even for consumer products, but hold your horses on the last one just for a little while.
The different departments and process owners will typically have claimed ownership of their particular parts of the process, making it look something like this:
This would typically be a traditional linear product engineering, manufacturing and distribution process. Each department has also selected IT tools that suit their particular needs in the process.
This in turn leads to information handovers both between company departments and IT tools, and due to the complexity of IT system integration, usually, as little as possible of data is handed from one system to the next.
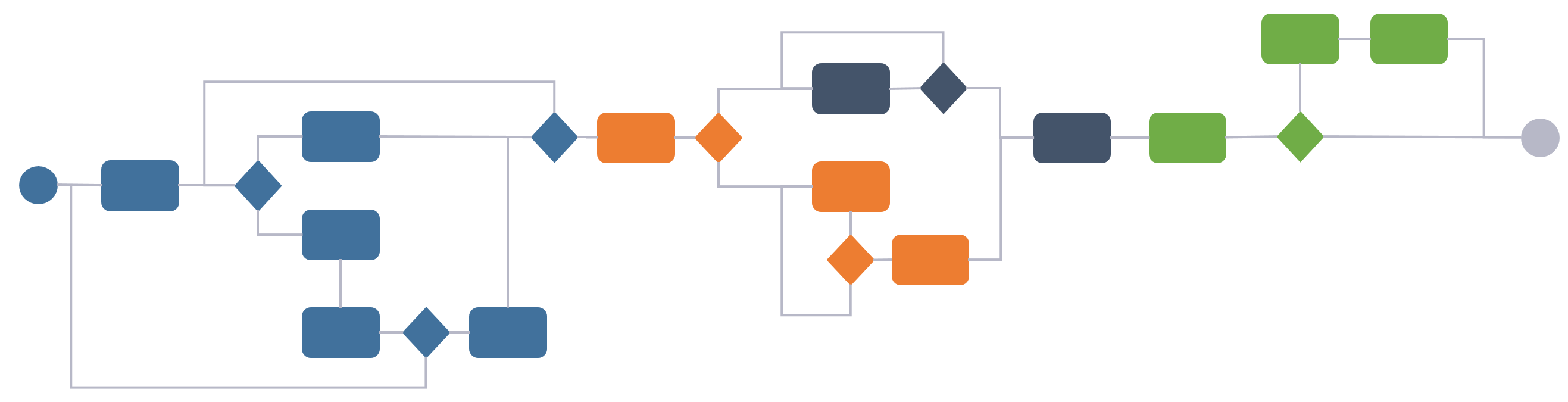
So far it has been quite straight forward to answer “who owns what data”, especially for the data that is actually created in the departments own IT system, however, the tricky one is the when in “ who owns what data when”, because the when implies that ownership of certain data is transferred from one department and/or IT system to the next one in the process. In a traditional linear one, such information would be “hurled over the wall” like this:
This in turn leads to information handovers both between company departments and IT tools, and due to the complexity of IT system integration, usually, as little as possible of data is handed from one system to the next.
So far it has been quite straight forward to answer “who owns what data”, especially for the data that is actually created in the departments own IT system, however, the tricky one is the when in “ who owns what data when”, because the when implies that ownership of certain data is transferred from one department and/or IT system to the next one in the process. In a traditional linear one, such information would be “hurled over the wall” like this:
Now, since as little information as possible flowed from one department / IT system to the next, each department would make it work as best as they could, and create or re-create information in their own system for everything that did not come directly through integration.
Only in cases where there were really big problems with lacking or clearly faulty data, an initiative would be launched to look at the process and any system integrations that would be affected.
The end result being that the accumulated information throughout the process that can be associated with the end product, that is to say the physical product sold to the consumer, is only a fraction of the actual sum of information generated in the different department’s processes and systems.
Now what happens when operations & services get more and more detailed information from each individual product in the field, and starts feeding that information back to the various departments and systems in the process?
Only in cases where there were really big problems with lacking or clearly faulty data, an initiative would be launched to look at the process and any system integrations that would be affected.
The end result being that the accumulated information throughout the process that can be associated with the end product, that is to say the physical product sold to the consumer, is only a fraction of the actual sum of information generated in the different department’s processes and systems.
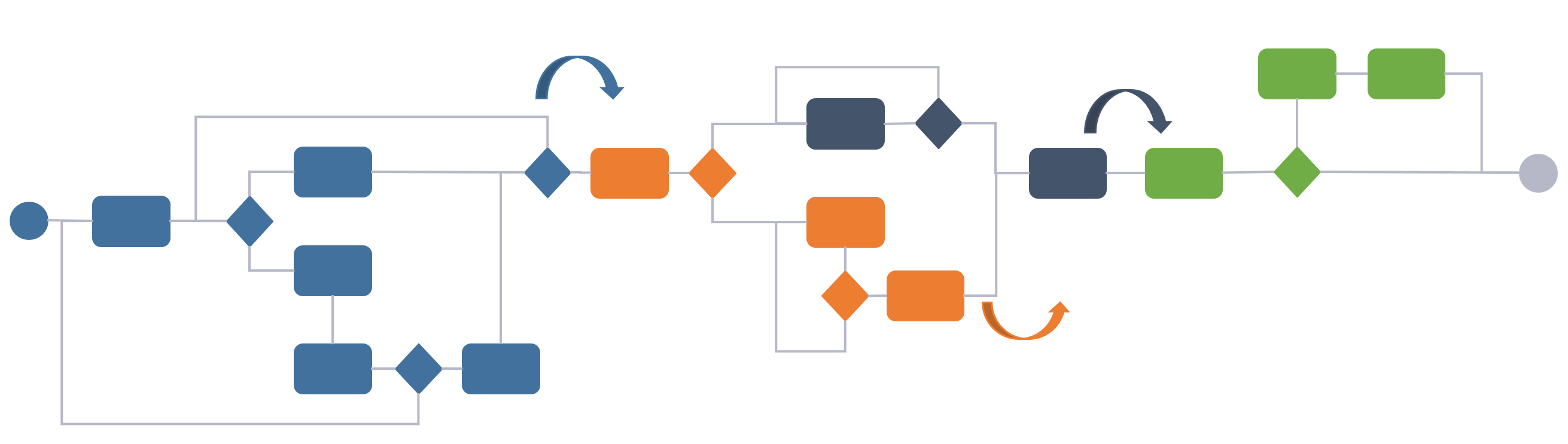
Now what happens when operations & services get more and more detailed information from each individual product in the field, and starts feeding that information back to the various departments and systems in the process?
The process will cease to be a linear one, it becomes circular with constant feedback of analyzed information flowing back to the different departments and IT systems.
Well what’s the problem you might ask.
The first thing that becomes clear is that each department with their systems does not have enough information to make effective use of all the information coming from operations, because they each have a quite limited set of data concerning mainly their discipline.
Secondly, the feedback loop is potentially constant or near real-time which will open up for completely new service offerings, however, the current process and infrastructure going from design through engineering and manufacturing was never built to tackle this kind of speed and agility.
Ironically, from a Product Lifecycle Management perspective, we’ve been talking about breaking down information and departmental silos in companies to utilize the L in PLM for as long as I can remember, however the way it looks now, it is probably going to be operations and the enablement of Internet Of Things and Big Data analytics that will force companies to go from strictly linear to circular processes.
And when you ultimately do, please always ask yourself “who should own what data when”, because ownership of data is not synonymous with the creation of data. Ownership is transferred along the process and accumulates to a full data set of the physically manufactured product until it is handed back again as a result of fault in the product or possible optimization opportunities for the product.
– And it will happen faster and faster
Bjorn Fidjeland
The header image used in this post is by Bacho12345 and purchased at dreamstime.com
Well what’s the problem you might ask.
The first thing that becomes clear is that each department with their systems does not have enough information to make effective use of all the information coming from operations, because they each have a quite limited set of data concerning mainly their discipline.
Secondly, the feedback loop is potentially constant or near real-time which will open up for completely new service offerings, however, the current process and infrastructure going from design through engineering and manufacturing was never built to tackle this kind of speed and agility.
Ironically, from a Product Lifecycle Management perspective, we’ve been talking about breaking down information and departmental silos in companies to utilize the L in PLM for as long as I can remember, however the way it looks now, it is probably going to be operations and the enablement of Internet Of Things and Big Data analytics that will force companies to go from strictly linear to circular processes.
And when you ultimately do, please always ask yourself “who should own what data when”, because ownership of data is not synonymous with the creation of data. Ownership is transferred along the process and accumulates to a full data set of the physically manufactured product until it is handed back again as a result of fault in the product or possible optimization opportunities for the product.
– And it will happen faster and faster
Bjorn Fidjeland
The header image used in this post is by Bacho12345 and purchased at dreamstime.com
 RSS Feed
RSS Feed
